JSSE: A JavaScript Engine Built by an Agent

In January, I came across a blog post by the author of one-agent-one-browser, a from-scratch browser built in Rust by a single person directing a single coding agent over a few days. No JavaScript support, though. I read it and thought: "How hard can it be to build a JavaScript engine the same way?"
Six weeks later, JSSE (JavaScript Simple Engine) became the first JavaScript engine I know of to pass 100% of test262 non-staging tests: all 98,426 scenarios across language/, built-ins/, annexB/, and intl402/. Not V8. Not SpiderMonkey. Not JavaScriptCore. A from-scratch engine in Rust, built entirely by Claude Code running in YOLO mode.
I didn't write a single line of Rust. Not one. The repository is a write-only data store from my perspective. I didn't even create the GitHub repo by hand; the agent did that too.
How It Started
It started with a conversation in a chat room about agentic coding and browsers. At 14:42 on January 27, I floated the idea: "OK, shall we embark on a JS engine from scratch to plug into that browser?" Seventeen minutes later I found the single-page spec and the key insight: "the great thing is we have test262, so we can create a feedback loop to create a JS engine that passes all the tests."
By 15:05 the repo was live. I set up the initial scaffolding (CLAUDE.md, PLAN.md, skills) and at 15:59 launched a Ralph Loop with a massive prompt to autonomously implement the engine task by task, run test262, review code, and commit.
At 16:02 the first commit landed. I went into a meeting. An hour later at 17:09 it was already executing JavaScript:
target/release/jsse -e 'function Foo(x) { this.x = x; } var f = new Foo(42); console.log(f.x);'
42
By 19:10 that evening it had reached 17.63% test262 pass rate. I signed off for the night. From zero to a functioning JS engine in Rust in about four hours.
The Numbers
| Metric | Value |
|---|---|
| Start date | January 27, 2026 |
| 100% non-staging test262 | March 9, 2026 (42 days) |
| Total commits | 592 |
| Total Rust | ~170,000 lines |
| Lines added (all time) | 929,475 |
| Lines removed (all time) | 448,317 |
| My hands-on-keyboard time | ~4 hours total |
That last number is the one that surprises people. Four hours spread across six weeks: 30 seconds here, two minutes there. The rest was the agent working autonomously.
How It Was Built
The setup was deliberately vanilla. Claude Code running in YOLO mode (auto-accept all tool use). No fancy orchestration. The plugins I used were:
/simplify, used maybe once or twice when files got too large and needed refactoringralph-wiggum-loop, the built-in autonomous loop plugin. I started with this but found it would get lost after a while (more on this below)- chiefloop.com, an external tool for running Claude Code overnight. Useful for long unattended runs, though it was missing some things from my usual workflow
The core of the project was PLAN.md, a task list that Claude generated itself from the ECMAScript spec and test262 submodules. My typical prompt was: "Read the first unfinished item in PLAN.md, plan and implement it, mark it as complete, commit and push." That was it. I never reviewed the code, never reviewed the plan, never read a diff. CLAUDE.md had the rules: no regressions allowed, always attempt to pass more tests than before. Sometimes I'd push back when Claude tried to skip a task it deemed too hard: "Why are you skipping this? We have to implement everything, so might as well tackle it now." But that was the extent of my guidance.
The longest successful unattended loop was 16 hours for the Temporal API implementation. I kicked it off before bed and came back to a full implementation of Instant, ZonedDateTime, PlainDateTime, PlainDate, PlainTime, Duration, Temporal.Now, IANA timezone support via ICU4X, and 12 calendar systems, with 4,482 test262 tests passing. Temporal is one of the largest and most complex proposals in recent ECMAScript history, and the agent handled it in a single overnight session.
What the Prompts Actually Looked Like
The previous section describes the workflow in the abstract: plan, implement, test, commit. But what did that actually look like day-to-day? Here are real prompts from the project, and they tell a story of their own.
The single most repeated prompt — the heartbeat of the entire project, appearing 20+ times — was this:
Take a look at PLAN.md and related plan/ files and file the next feature that has most impact on test262 pass rate. Come up with 3 possible features to work on and their respective impact and once we know that we can choose one.
That was the core loop. I didn't pick what to work on; I asked the agent to analyze test262 coverage gaps, propose options ranked by impact, and then I'd pick one (or just say "go"). Most of my interaction was at this level: strategic, not tactical.
When things went sideways, the prompts shifted to debugging:
What happened? What were you trying to do? Why is this bash running for 40 minutes?
Long-running sessions would sometimes stall on a single test or get stuck in a compilation loop. The fix was usually to kill the session and restart with a narrower scope.
As the project matured, I got more ambitious with parallelism:
How about we delegate each of these tasks to a team of agents to plan and implement where each agent is working in its own worktree and then you merge it all together once it's complete? That would likely give us ~300 new passes?
Let's create 3 plans, then I will start 3 agents to work on each in separate worktrees.
Claude Code supports worktrees — isolated git branches that multiple agents can work on simultaneously. This is how the hardest features got done: split the work into independent tracks, run them in parallel, merge. The Temporal API implementation used this pattern heavily.
Some prompts were just green lights for marathon sessions:
Yes. Start and complete all phases, committing in between.
We should probably tackle option A straight ahead and not shy away. Create a plan to deal with array holes, then implement.
That last one is about array holes — one of JavaScript's gnarliest semantic corners. [1, , 3] has a hole at index 1 that behaves differently from undefined in subtle, spec-mandated ways. The agent handled it, but it took a dedicated session.
The endgame prompts (98%+) were the most interesting, because the nature of the work changed completely. Instead of implementing features, we were hunting individual test failures:
We are so close to full compliance. What's missing? Let's just find the first category not passing 100% and deal with that.
Which of these will close up 100% compliance on a specific category?
And the final push to 100%:
We have a @PLAN.md and a bunch of @plan/ files. Our ultimate goal is 100% test262 compliance. We are close but need to close a few gaps. Your task is to create a plan to take us to 100% compliance — forward progress, no regressions.
The pattern across all of these is that I was never telling the agent how to implement anything. I was setting goals, choosing priorities, and occasionally unblocking. The agent did the engineering.
The Pass Rate Curve
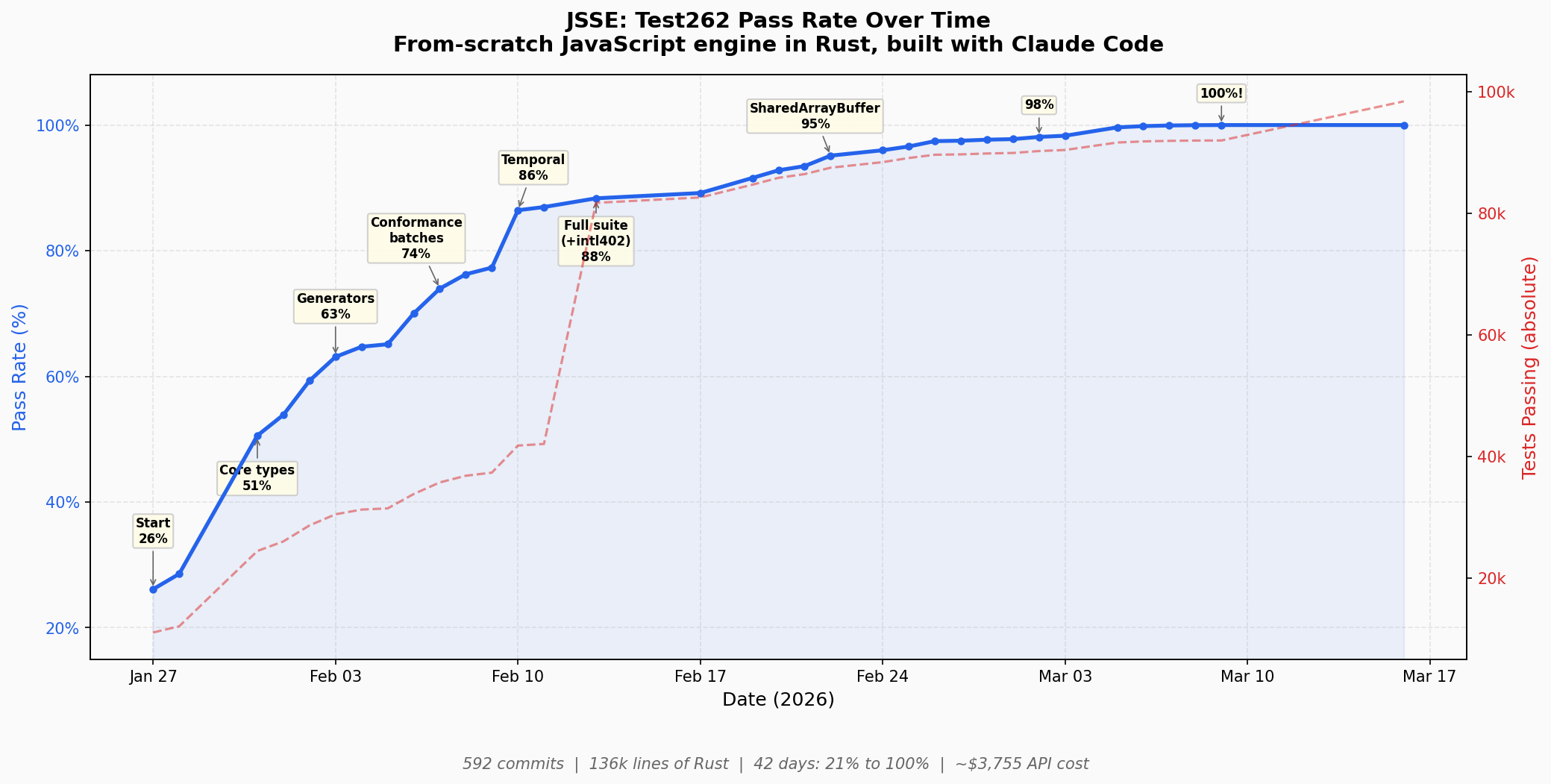
The chart tells the story better than I can. A few milestones worth calling out:
| Date | Rate | What happened |
|---|---|---|
| Jan 27 | 26% | Project kickoff: lexer, parser, basic interpreter |
| Jan 31 | 51% | String.prototype wiring bug fix exposed ~11k tests (+23% in a single day) |
| Feb 3 | 63% | Generators via state machine approach |
| Feb 10 | 86% | Temporal API phase 1 |
| Feb 13 | 88% | Full suite expansion: added intl402, test count nearly doubled (~48k → ~92k), pass rate still went up |
| Feb 22 | 95% | SharedArrayBuffer + Atomics (868 new passes in one day) |
| Mar 5 | 99.6% | Massive parser early-errors batch (274 fixes) |
| Mar 9 | 100% | Array.fromAsync was the final fix |
The Jan 31 jump is my favorite. A single bug fix in how String.prototype was wired up unblocked about 11,000 tests overnight. That's the kind of thing where having the full test262 suite as your feedback signal is invaluable; you find bugs by their blast radius.
Engine Comparison
I ran the same test262 suite against Node.js and Boa (another Rust-based JS engine) for comparison. Same checkout, same harness, same timeout, same machine (128-core):
| Engine | Version | Scenarios | Pass | Fail | Rate |
|---|---|---|---|---|---|
| JSSE | latest | 101,234 | 101,044 | 190 | 99.81% |
| Boa | v0.21 | 91,986 | 83,260 | 8,726 | 90.51% |
| Node | v25.8.0 | 91,986 | 79,201 | 11,986 | 86.86% |
Some important caveats: Node's failures are dominated by Temporal (not shipped in Node 25, that's 8,980 of its 11,986 failures). Module tests (799 scenarios) are skipped for Node because the test adapter can't run ES modules through it. Boa's main gaps are parser-level (assignment target validation, class destructuring, RegExp property escapes). These are mature, production-quality engines being compared on a metric they weren't specifically optimizing for, so take the comparison for what it is.
JSSE's scenario count is higher (101,234 vs 91,986) because it includes the full staging test suite. On non-staging tests, JSSE is at a flat 100%.
I also ran JSSE against the acorn test suite as a real-world sanity check beyond test262. All 13,507 acorn tests pass.
A Note on Staging Tests
At one point I thought JSSE was passing staging tests too. It wasn't. run-test262.py wasn't actually running them. When I finally ran the staging suite explicitly, things got interesting.
The non-staging suite is well-maintained and internally consistent. Staging is where proposed tests live before promotion, and it shows. JSSE currently passes 2,762 of 2,808 staging scenarios (98.36%). The remaining failures fall into three categories: flaky timeouts, libm precision gaps, and, most interestingly, what appear to be bugs in the test suite itself.
For example, six staging tests use a shared harness function that relies on eval-declared variables leaking into the enclosing scope, which strict mode explicitly prevents. These tests fail on both JSSE and Node. They need a noStrict flag upstream. Another case: two staging tests expect AnnexB hoisting behavior for block-scoped function arguments() declarations that directly contradicts a main-suite test. The main suite reflects a recent spec change that no major engine has implemented yet. JSSE follows the spec, so the main-suite test passes and the staging tests fail.
When the test suite you're targeting starts testing you back, that's a good sign.
What About Performance?
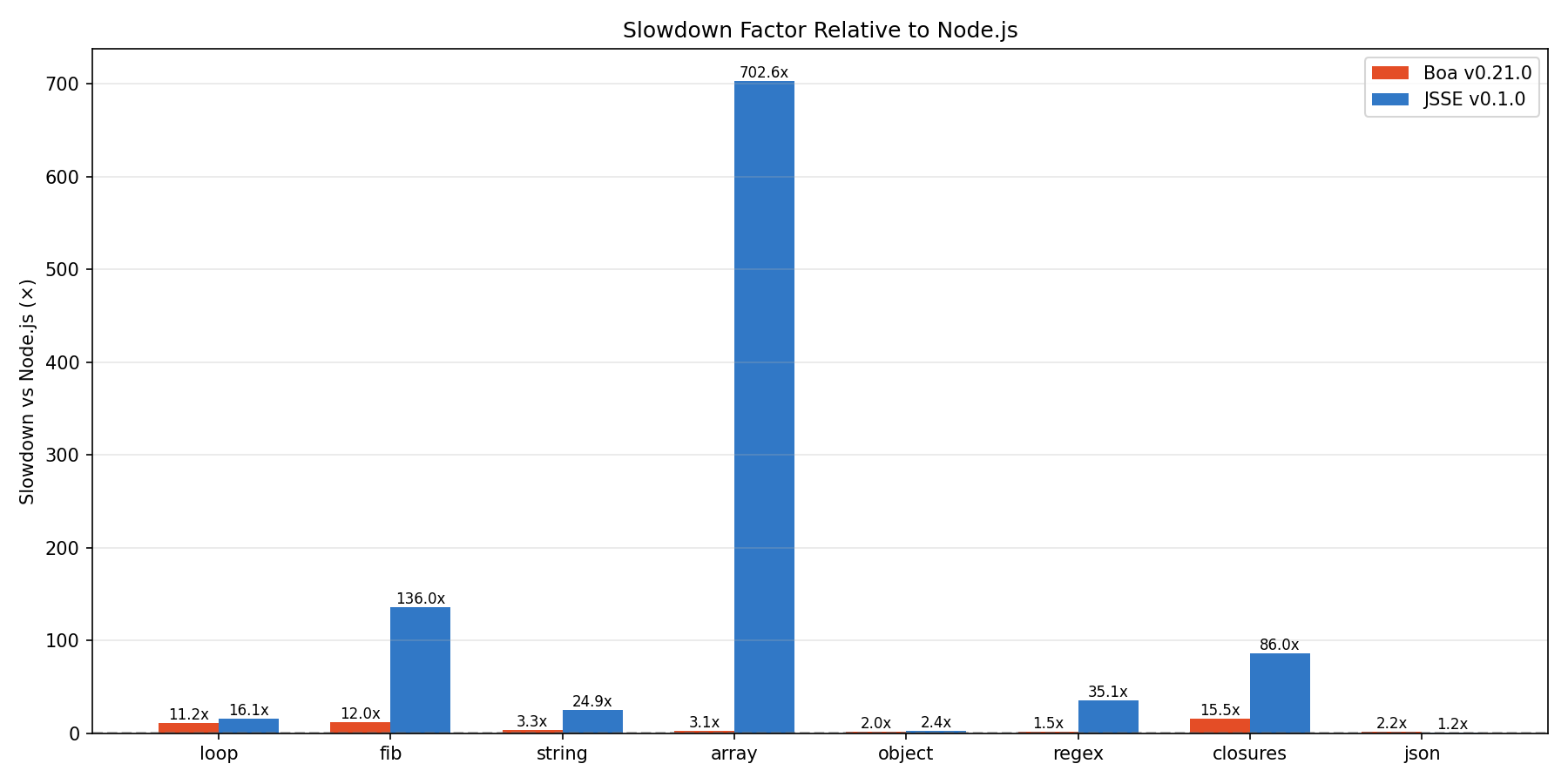
Bad. Intentionally so. Zero effort was spent on optimization. JSSE is a pure tree-walking interpreter with no bytecode compilation. Here are some microbenchmarks against Node (V8) and Boa:
| Benchmark | Node v18 | Boa v0.21 | JSSE v0.1 | JSSE vs Node |
|---|---|---|---|---|
| loop | 0.18s | 2.02s | 2.90s | 16x |
| fib | 0.21s | 2.53s | 28.57s | 136x |
| string | 0.19s | 0.62s | 4.74s | 25x |
| array | 0.17s | 0.53s | 119.45s | 703x |
| object | 0.35s | 0.69s | 0.85s | 2.4x |
| regex | 0.16s | 0.24s | 5.62s | 35x |
| closures | 0.18s | 2.79s | 15.48s | 86x |
| json | 0.20s | 0.44s | 0.25s | 1.2x |
The range is enormous: from 1.2x (JSON, where JSSE actually beats Boa) to 703x (array operations). The fib benchmark is recursive Fibonacci, which hammers function call overhead, and 136x is exactly what you'd expect from a tree-walker that re-traverses the AST on every call. The array benchmark is the worst case, likely hitting a pathological path in the array prototype implementation.
Comparing against Boa is more fair since both are interpreters in Rust. JSSE is roughly 1.2x to 225x slower than Boa depending on the benchmark. Object operations and JSON are actually competitive.
The test262 suite itself reveals where the pain is. All 30 of the slowest tests are RegExp Unicode property escape tests (\p{...}), each taking 64–84 seconds. The slowest, Script_Extensions_-_Sharada.js, hits 84 seconds. These tests compile and run regexes that enumerate thousands of Unicode codepoints, and the bottleneck is byte-level WTF-8 regex matching for Unicode property classes. Out of 198,258 total test scenarios, 900 take over 10 seconds and 1,062 take over 1 second. Everything else finishes fast. The long tail is almost entirely regex.
This is fine. Correctness was the only goal. Performance is the obvious next step.
The Cost
I used a Claude Code Max 20x subscription for this project, so I didn't pay per-token. But ccusage tracks what the equivalent API cost would have been, and the number is interesting for context: $4,618.94 across 302 sessions over 47 days. The breakdown by model:
| Model | Cost (API equivalent) | Share |
|---|---|---|
| Claude Opus 4.6 | $4,062.91 | 88% |
| Claude Sonnet 4.6 | $345.54 | 7.5% |
| Claude Haiku 4.5 | $124.83 | 2.7% |
| Claude Sonnet 4.5 | $45.56 | 1% |
| Claude Opus 4.5 | $40.11 | 0.9% |
Opus 4.6 did the vast majority of the heavy lifting. Haiku was used for background tasks like subagent searches. The total token count was about 8.9 billion, but aggressive prompt caching kept costs manageable; cache read tokens alone were 8.8 billion.
To put it in perspective: $4,619 in API-equivalent cost for a 170,000-line Rust codebase that passes 100% of test262. That's roughly $0.03 per line of code, or about $47 per percentage point of test262 compliance.
What I Learned
The plan matters more than the code. Claude generated the entire PLAN.md itself from the spec and test262 submodules. I didn't write it, didn't review it, just accepted it. And it worked. But looking back, the plan's quality was the single biggest lever on the project's speed. Claude picked a reasonable feature order, but it made some architectural decisions early on (like how to handle generators, how to structure the GC, how to deal with WTF-8 strings) that caused expensive rework later. If I had invested time upfront researching the right architecture and feeding that into the plan, I'm fairly confident this project would have taken half the time. The lesson isn't "you must write the plan yourself," it's "make sure the plan is good, however it gets made."
test262 is an incredible feedback signal. Having a comprehensive, well-structured test suite that the agent can run autonomously is what makes this kind of project possible. The agent doesn't need to understand JavaScript semantics deeply; it needs to make the number go up while not making it go down. test262 provides exactly that signal.
Agents get lost in long contexts. This needs some explanation. Claude Code automatically compacts the conversation when it approaches the context limit (which was 200k tokens at the time of this project). Compaction summarizes older messages to free up space, but it inevitably loses detail: which specific tests were failing, what approach was being tried, what the error messages said. After several rounds of compaction in a long-running task, Claude would visibly degrade. It would go in circles, attempting the same fix repeatedly. It would pass some tests but regress others, then try to fix the regressions and break something else. My fix was to stop the session, split the task into smaller pieces, and start fresh. A new session with a focused prompt ("implement SharedArrayBuffer") worked far better than a long-running loop that had been through multiple compactions. The sweet spot was: one feature per session, plan it, implement it, run tests, stop.
Re-architecture is expensive but not catastrophic. There was a point where Claude realized the architecture wasn't right for async functions and had to go back and restructure things. It took longer than it should have, but it worked. A human architect who understood the problem space would have avoided this, which circles back to the first point.
Rust is good for agentic coding. I chose Rust explicitly because I believe it's currently the best language for agent-driven development. The type system and compiler catch a massive class of bugs before runtime, which means the agent spends less time debugging and more time making forward progress. The strict compiler is essentially a second feedback signal alongside test262.
What's Next
Performance. The engine is a pure tree-walker, and the lowest-hanging fruit is bytecode compilation and a simple VM. There's probably 10-100x to be gained just from eliminating repeated AST traversal. Beyond that, inline caches, hidden classes, and eventually JIT compilation if I want to get serious.
But honestly, the point of JSSE was never to build a production JavaScript engine. It was to explore what's possible with current agentic coding tools, and to learn about agent workflows in the process. On both counts, I'm satisfied with the result.
Conclusions
The tools are amazing and the models are incredible, but this is just the beginning. Agentic coding is already changing the way people work, and I believe it will revolutionize software production (I've written about some of my ideas on this). In the near future, writing a JS engine from scratch and optimizing it to be faster than anything else will be a walk in the park, literally the duration of a walk in the park. I've learned a lot from this experiment and I'll keep having fun with it.
The code is at github.com/pmatos/jsse. MIT licensed. If you want to run test262 yourself, the README has full reproduction instructions. Contributions to JSSE are welcome, but please keep them agentic.