FEX x87 Stack Optimization
In this blog post, I will describe my recent work on improving and optimizing the handling of x87 code in FEX. This work landed on July 22, 2024, through commit https://github.com/FEX-Emu/FEX/commit/a1378f94ce8e7843d5a3cd27bc72847973f8e7ec (tests and updates to size benchmarks landed separately).
FEX is an ARM64 emulator of Intel assembly and, as such, needs to be able to handle things as old as x87, which was the way we did floating point pre-SSE.
Consider a function to calculate the well-known Pythagorean Identity:
float PytIdent(float x) {
return sinf(x)*sinf(x) + cosf(x)*cosf(x);
}Here is how this can be translated into assembly:
sub rsp, 4
movss [rsp], xmm0
fld [rsp]
fsincos
fmul st0, st0
fxch
fmul st0, st0
faddp
fstp [rsp]
movss xmm0, [rsp]
These instructions will take x from register xmm0 and return the result of the identity (the number 1, as we expect) to the same register.
A brief visit to the x87 FPU
The x87 FPU consists of 8 registers (R0 to R7), which are aliased to the MMX registers - mm0 to mm7. The FPU uses them as a stack and tracks the top of the stack through the TOS (Top of Stack) or TOP (my preferred way to refer to it), which is kept in the control word. To understand how it all fits together, I will describe the three most important components of this setup for the purpose of this post:
- FPU Stack-based operation
- Status register
- Tag register
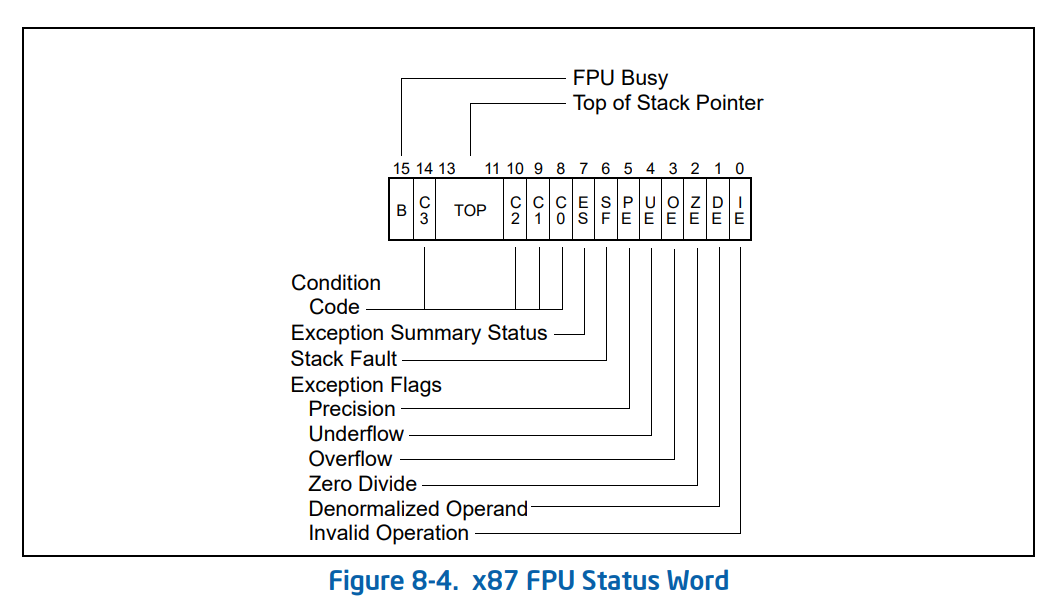
From the Intel spec, these components look like this (image labels are from the Intel in case you need to refer to it):

The 8 registers are labelled as ST0-ST7 relative to the position of TOP. In the case above TOP is 3; therefore, the 3rd register is ST0. Since the stack grows down, ST1 is the 4th register and so on until it wraps around. When the FPU is initialized TOP is set to 0. Once a value is loaded, the TOP is decreased, its value becomes 7 and the first value added to the stack is in the 7th register. Because the MMX registers are aliased to the bottom 64 bits of the stack registers, we can also refer to them as MM0 to MM7. This is not strictly correct because the MMX registers are 64 bits and the FPU registers are 80 bits but if we squint, they are basically the same.
The spec provides an example of how the FPU stack works. I copy the image here verbatim for your understanding. Further information can be found in the spec itself.
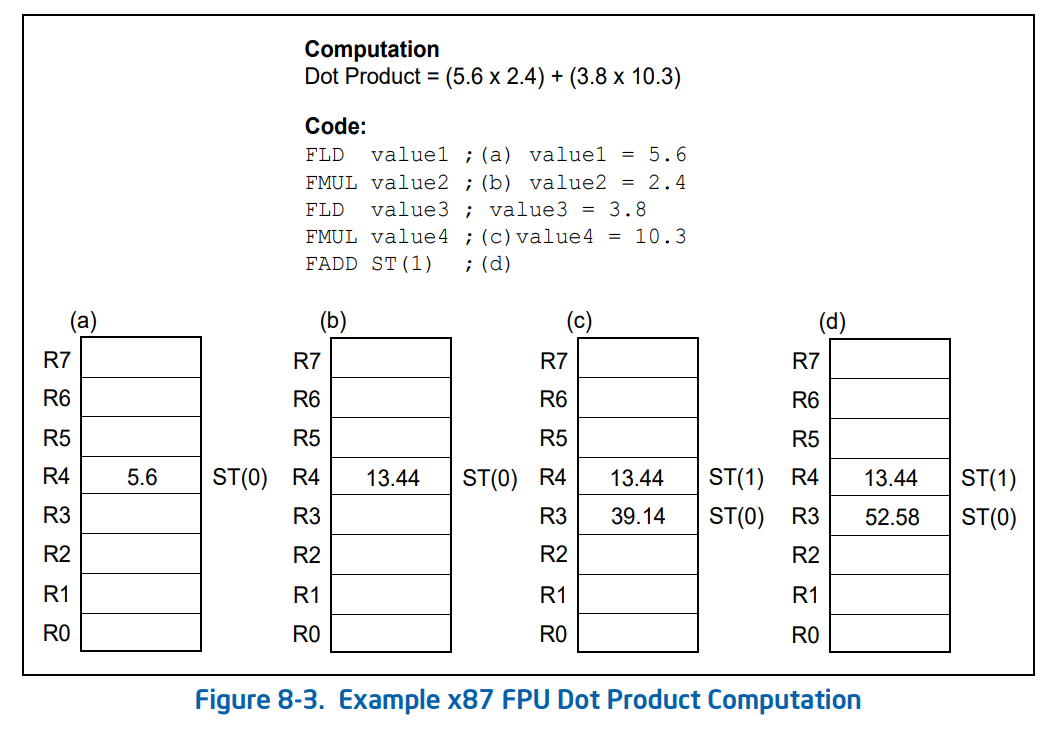
The TOP value is stored along with other flags in the FPU Status Word, which we won't discuss in detail here.
And the tag word marks which registers are valid or empty. The Intel spec also allows marking the registers as zero or special. At the moment, tags in FEX are binary, marking the register as valid or invalid. Instead of two bits per register, we only use one bit of information per register.

Current issues
The way things worked in FEX before this patch landed is that stack based operations would essentially always lower to perform three operations:
- Load stack operation argument register values from special memory location;
- Call soft-float library to perform the operation;
- Store result in special memory location;
For example, let's consider the instruction FADDP st4, st0. This instruction performs st0 <- f80add(st4, st0) && pop(). In x87.cpp, the lowering of this instruction involved the following steps:
- Load current value of top from memory;
- With the current value of top, we can load the values of the registers in the instruction, in this case st4 and st0 since they are at a memory offset from top;
- Then we call the soft-float library function to perform 80-bit adds;
- Finally we store the result into st4 (which is a location in memory);
- And pop the stack, which means marking the current top value invalid and incrementing top;
In code with a lot of x87 usage, these operations become cumbersome and data movement makes the whole code extremely slow. Therefore, we redesigned the x87 system to cope better with stack operations. FEX support a reduced precision mode that uses 64bit floating points rather than 80 bits, avoiding the soft-float library calls and this work applies equally to the code in reduced precision mode.
The new pass
The main observation to understand the operation of the new pass is that when compiling a block of instructions, where multiple instructions are x87 instructions, before code generation we have an idea of what the stack will look like, and if we have complete stack information we can generate much better code than the one generated on a per-instruction basis.
Instead of lowering each x87 instruction in x87.cpp to its components as discussed earlier, we simply generate stack operation IR instructions (all of these added new since there were no stack operations in the IR). Then an optimization pass goes through the IR on a per block basis and optimizes the operations and lowers them.
Here’s a step-by-step explanation of how this scheme works for the code above. When the above code gets to the OpcodeDispatcher, there’ll be one function a reasonable amount of opcodes, but generally one per functionality, meaning that although there are several opcodes for different versions of fadd, there is a single function in OpcodeDispatcher for x87 (in x87.cpp) implementing it.
Each of these functions will just transform the incoming instruction into an IR node that deals with the stack. These stack IR operations have Stack in its name. See IR.json for a list of these.
| x86 Asm | IR nodes |
|---|---|
fld qword [rsp] | LoadMem + PushStack |
fsincos | F80SinCosStack |
fmul st0, st0 | F80MulStack |
fxch | F80StackXchange |
fmul st0, st0 | F80MulStack |
faddp | F80AddStack + PopStackDestroy |
fstp qword [rsp] | StoreStackMemory + PopStackDestroy |
The IR will then look like:
%9 i64 = LoadRegister #0x4, GPR
%10 i128 = LoadMem FPR, %9 i64, %Invalid, #0x10, SXTX, #0x1
(%11 i0) PushStack %10 i128, %10 i128, #0x10, #0x1
(%12 i0) F80SINCOSStack
%13 i64 = Constant #0x0
(%14 i8) StoreContext GPR, %13 i64, #0x3fa
(%15 i0) F80MulStack #0x0, #0x0
(%16 i0) F80StackXchange #0x1
%17 i64 = Constant #0x0
(%18 i8) StoreContext GPR, %17 i64, #0x3f9
(%19 i0) F80MulStack #0x0, #0x0
(%20 i0) F80AddStack #0x1, #0x0
(%21 i0) PopStackDestroy
%23 i64 = LoadRegister #0x4, GPR
(%24 i0) StoreStackMemory %23 i64, i128, #0x1, #0x8
(%25 i0) PopStackDestroy
The Good Case
Remember that before this pass, we would have never generated this IR as is. There were no stack operations, therefore each of these F80MulStack operations, would generate loads from the MMX registers that are mapped into memory for each of the operands, call to F80Mul softfloat library function and then a write to the memory mapped MMX register to write the result.
However, once we get to the optimization pass a see a straight line block line this, we can step through the IR nodes and create a virtual stack with pointers to the IR nodes. I have sketched the stacks for the first few loops in the pass.
The pass will only process x87 instructions, these are the one whose IR nodes are marked with "X87: true in IR.json. Therefore the first two instructions above:
%9 i64 = LoadRegister #0x4, GPR
%10 i128 = LoadMem FPR, %9 i64, %Invalid, #0x10, SXTX, #0x1
are ignored. But PushStack is not. PushStack will literally push the node into the virtual stack.
(%11 i0) PushStack %10 i128, %10 i128, #0x10, #0x1

Internally before we push the node into our internal stack, we update the necessary values like the top of the stack. It starts at zero and it's decremented to seven, so the value %10 i128 is inserted in what we'll call R7, now ST0.
Next up is the computation of SIN and COS. This will result in SIN ST0 replacing ST0 and then pushing COS ST0, where the value in ST0 here is %10.
(%12 i0) F80SINCOSStack

Then we have two instructions that we just don't deal with in the pass, these set the C2 flag to zero - as required by FSINCOS.
%13 i64 = Constant #0x0
(%14 i8) StoreContext GPR, %13 i64, #0x3fa
Followed by a multiplication of the stack element to square them. So we square ST0.
(%15 i0) F80MulStack #0x0, #0x0

The next instruction swaps ST0 with ST1 so that we can square the sine value.
(%16 i0) F80StackXchange #0x1

Again, similarly two instructions that are ignored by the pass, which set flag C1 to zero - as required by FXCH.
%17 i64 = Constant #0x0
(%18 i8) StoreContext GPR, %17 i64, #0x3f9
And again we square the value at the top of the stack.
(%19 i0) F80MulStack #0x0, #0x0

We are almost there - to finish off the computation we need to add these two values together.
(%20 i0) F80AddStack #0x1, #0x0
In this case we add ST1 to ST0 and store the result in ST1.

This is followed by a pop of the stack.
(%21 i0) PopStackDestroy
As expected this removed the F80Mul from the top of the stack, leaving us with the result of the computation at the top.

OK - there are three more instructions.
%23 i64 = LoadRegister #0x4, GPR
(%24 i0) StoreStackMemory %23 i64, i128, #0x1, #0x8
(%25 i0) PopStackDestroy
The first two store the top of the stack to memory, which is the result of our computation and which maths assures us it's 1. And then we pop the stack just to clean it up, although this is not strictly necessary since we are finished anyway.
Note that we have finished analysing the block, and played it through in our virtual stack. Now we can generate the instructions that are necessary to calculate the stack values, without always load/stor'ing them back to memory. In addition to generating these instructions we also generate instructions to update the tag word, update the top of stack value and save whatever remaining values in the stack at the end of the block into memory - into their respective memory mapped MMX registers. This is the good case where all the values necessary for the computation were found in the block. However, this is not necessarily always the case.
The Bad Case
Let's say that FEX for some reason breaks the beautiful block we had before into two:
Block 1:
%9 i64 = LoadRegister #0x4, GPR
%10 i128 = LoadMem FPR, %9 i64, %Invalid, #0x10, SXTX, #0x1
(%11 i0) PushStack %10 i128, %10 i128, #0x10, #0x1
(%12 i0) F80SINCOSStack
%13 i64 = Constant #0x0
(%14 i8) StoreContext GPR, %13 i64, #0x3fa
(%15 i0) F80MulStack #0x0, #0x0
(%16 i0) F80StackXchange #0x1
%17 i64 = Constant #0x0
(%18 i8) StoreContext GPR, %17 i64, #0x3f9
Block 2:
(%19 i0) F80MulStack #0x0, #0x0
(%20 i0) F80AddStack #0x1, #0x0
(%21 i0) PopStackDestroy
%23 i64 = LoadRegister #0x4, GPR
(%24 i0) StoreStackMemory %23 i64, i128, #0x1, #0x8
(%25 i0) PopStackDestroy
When we generate code for the first block, there are absolutely no blockers and we run through it exactly as we did before, except that after StoreContext, we reach the end of the block and our virtual stack is in this state:
At this point, we'll do what we said we always do before at the end of the block. We save the values in the virtual stack to the respective MMX registers in memory mapped locations: %36 is saved to MM7 and %34 is saved to MM6. The TOP is recorded to be 6 and the tags for MM7 and MM6 are marked to be valid. Then we exit the block. And start analyzing the following block.
When we start the pass for the following block, our virtual stack is empty. We have no knowledge of virtual stacks for previous JITTed blocks, and we see this instruction:
(%19 i0) F80MulStack #0x0, #0x0
We cannot play through this instruction in our virtual stack because it multiplies the value in ST0 with itself and our virtual stack does not have anything in ST0. It's empty after all.
In this case, we switch to the slow path that does exactly what we used to do before this work. We load the value of ST0 from memory by finding the current value for TOP and loading the respective register value, issue the F80Mul on this value and storing it back to the MMX register. This is then done for the remainder of the block.
The Ugly Case
The ugly case is when we actually force the slow path, not because we don't have all the values in the virtual stack but out of necessity.
There are a few instructions that trigger a _StackForceSlow() and forces us down the slow path. These are: FLDENV, FRSTOR, FLDCW. All of these load some part or all of the FPU environment from memory and it triggers a switch to the slow path so that values are loaded properly and we can then use those new values in the block. It is not impossible to think we could at least in some cases, load those values from memory, try to rebuild our virtual stack for the current block and continue without switching to the slow path but that hasn't been yet done.
There are a few instructions other instructions that trigger a _SyncStackToSlow(), which doesn't force us down the slow path but instead just updates the in-memory data from the virtual stack state. These are: FNSTENV, FNSAVE, and FNSTSW. All of these store some part or all of the FPU environment into memory and it ensures that the values in-memory are up-to-date so that the store doesn't use obsolete values.
Results
In addition to the huge savings in data movement from the loads and stores of register values, TOP and tags for each stack instruction, we also optimize memory copies through the stack. So if there's a bunch of value loaded to the stack, which are then stored to memory, we can just memcopy these values without going through the stack.
In our code size validation benchmarks from various Steam games, we saw significant reductions in code size. These size code reductions saw a similarly high jump in FPS numbers. For example:
| Game | Before | After | Reduction |
|---|---|---|---|
| Half-Life (Block 1) | 2034 | 1368 | 32.7% |
| Half-Life (Block 2) | 838 | 551 | 34.2% |
| Oblivion (Block 1) | 34065 | 25782 | 24.3% |
| Oblivion (Block 2) | 22089 | 16635 | 24.6% |
| Psychonauts (Block 1) | 20545 | 16357 | 20.3% |
| Psychonauts Hot Loop (Matrix Swizzle) | 2340 | 165 | 92.9% |
Future work
The bulk of this work is now complete, however there are a few details that still need fixing. There's still the mystery of why Touhou: Luna Nights works with reduced precision but not normal precision (if anything you would expect it to be the other way around). Then there's also some work to be done on the interface between the FPU state and the MMX state as described in "MMX/x87 interaction is subtly broken".
This is something I am already focusing on and will continue working on this until complete.